Learning Personalized End-to-End Goal-Oriented Dialog
Abstract
Most existing works on dialog systems only consider conversation content while neglecting the personality of the user the bot is interacting with, which begets several unsolved issues. In this paper, we present a personalized end-to-end model in an attempt to leverage personalization in goal-oriented dialogs. We first introduce a Profile Model which encodes user profiles into distributed embeddings and refers to conversation history from other similar users. Then a Preference Model captures user preferences over knowledge base entities to handle the ambiguity in user requests. The two models are combined into the Personalized MemN2N. Experiments show that the proposed model achieves qualitative performance improvements over state-of-the-art methods. As for human evaluation, it also outperforms other approaches in terms of task completion rate and user satisfaction.
Related Work and Resources
The personalization of dialog systems is a meaningful task, which has not received much attention in the past few years. When this paper was initiated in Jan 2018, there were few publicly available datasets that allow researchers to train dialog systems with personalized information. But recently, thanks to the researchers from FAIR, several brand new personalized dialog datasets have been released to the research community.
Zhang et al. (2018) construct a Persona-Chat dataset and release it on ParlAI. The authors crowdsource a set of 1K+ personas, each of which consists of at least 5 natural sentences to describe the user profile. Each dialog in this dataset is produced by two human workers assigned each with a random persona from the pool. The dataset also serves as the resource of a shared-competition in NIPS 2018. This may hopefully attracts more researchers’ attention on this particular task. Mazare et al. (2018) then build a personalized dialog dataset with the same form of persona with that in Zhang et al. (2018) based on Reddit corpus. This dataset has a much larger size (5M personas and 700M dialogs), while it is in a single-turn style rather than multi-turn, which is a big weakness as the research on multi-turn dialog systems are much more important nowadays. Besides, some previous built datasets based on movie scripts or Twitter comments can be seen as alternatives. More details can be found in Section 2 of the paper.
It should be mentioned that all the resources introduced above are designed for chit-chat. Another important type of conversational agents is goal-oriented dialog systems, including personal assistants, customer service and restaurant reservation service, etc. These scenarios are really common in our daily life and thus personalization is also worth investigated. Unfortunately, the research on this track remains unexplored, and there is only one publicly available dataset suitable for this task currently, called personalized bAbI dialog corpus (Joshi et al., 2017), which is also available on ParlAI.
The goals of personalization in goal-oriented dialog are much different from those in chit-chat, which will be discussed in the next paragraph. We present several novel approaches in this paper, hoping to bring other researchers inspirations on the future directions.
Background and Intuition
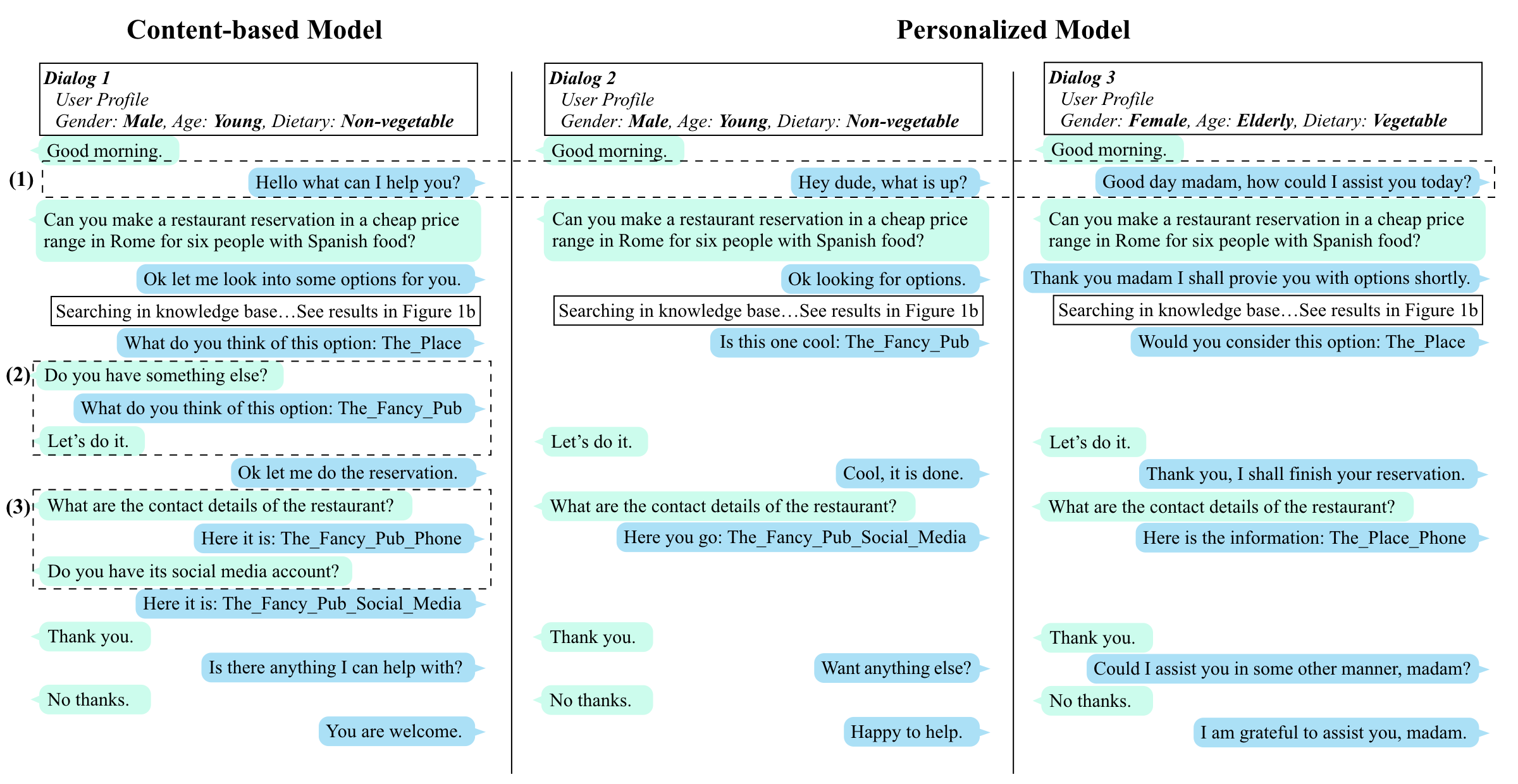
Figure 1(a): Three example dialogs are chosen from the personalized bAbI dialog dataset. Personalized and content-based responses are generated by the Personalized MemN2N and a standard memory network, respectively.

Figure 1(b): Examples of valid candidates from a knowledge base that match the user request.
Let’s take a look at the example in Figure 1 to see what is wrong with conventional content-based goal-oriented dialog systems.
The conversations happen in a restaurant reservation scenario. The agent is responsible for recommending restaurants according to the user request and providing extra information if necessary. In all the three dialogs, the user utterances are the same. The first and the second dialogs are with a young male with non-vegetable dietary, and the third one is with an elderly female with vegetable dietary. The two restaurants in Figure 1(b) are valid candidates from a knowledge base that match the user request. We can see that
- The responses from the content-based model are plain and boring, and it is not able to adjust appellations and language styles like the personalized model.
- In the recommendation phase, the content-based model can only provide candidates in a random order, while a personalized model can change recommendation policy dynamically, and in this case, match the user dietary (recommends
The_Fancy_Pubfor the young male andThe_Placefor elderly female). - The word
contactcan be interpreted intophoneorsocial mediacontact information in the knowledge base. Instead of choosing one randomly, the personalized model handles this ambiguity based on the learned fact that young people prefer social media account while the elders prefer phone number.
These problems in the above example reflect three common issues with current models:
- The inability to adjust language style flexibly (Herzig et al., 2017).
- The lack of a dynamic conversation policy based on the interlocutor’s profile (Joshi et al., 2017).
- The incapability of handling ambiguities in user requests.
Correspondingly, the goals of personalization in goal-oriented dialog systems are solving these issues. Note that they are very different from personalization in chit-chat. Instead of assigning a consistent personality to agents, personalized agents for goal-oriented dialog pay more attention to the user persona and aim to make agents more adaptive to different kinds of interlocutors, and therefore improve the task completion rate and user satisfaction.
Model Overview
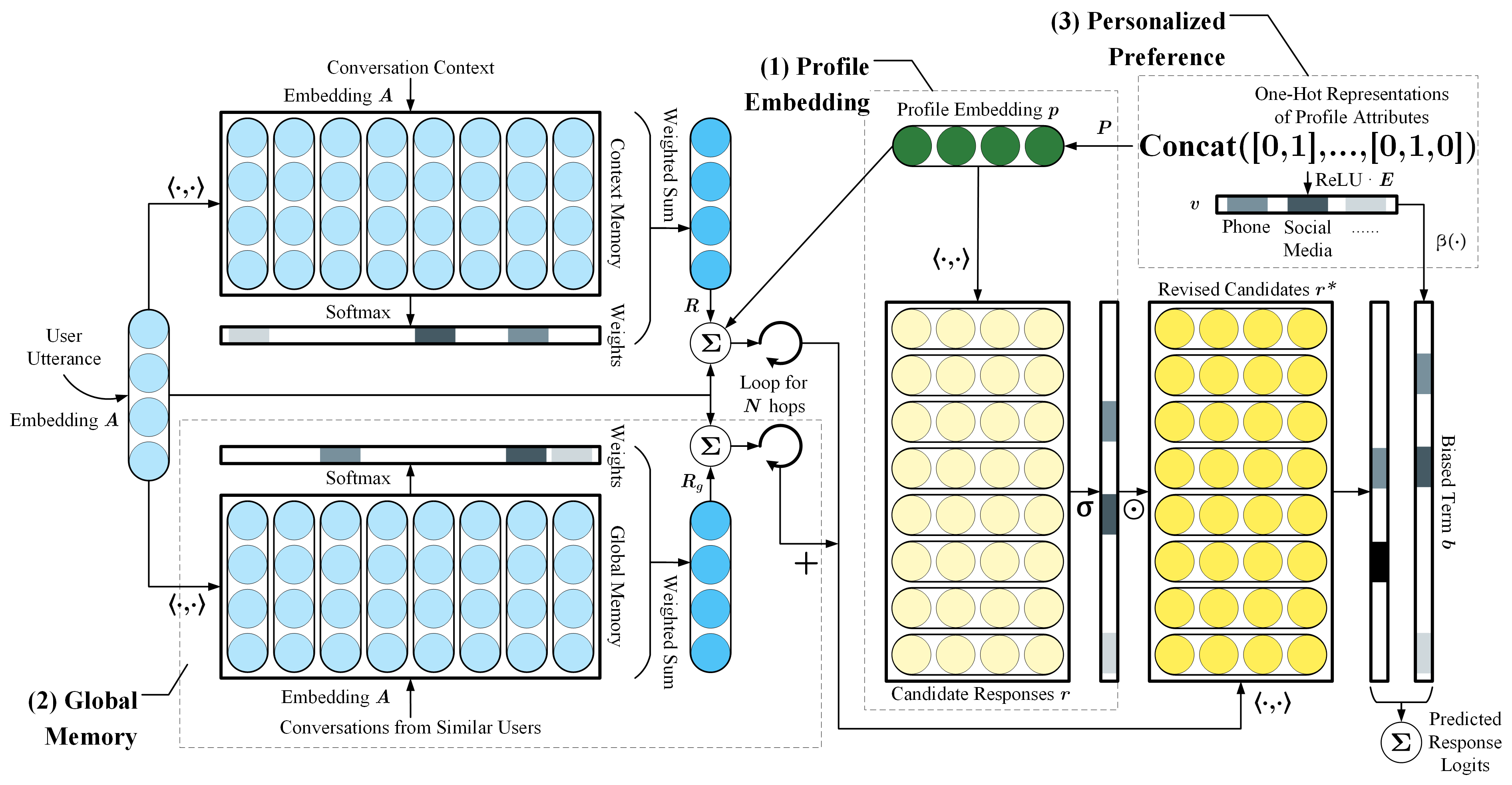
Figure 2: Personalized MemN2N architecture.
Our work is in the vein of the memory network models for goal-oriented dialog from Bordes et al. (2017). Our model, Personalized MemN2N, consists of three main components: profile embedding, global memory and personalized preference. Here we just provide a (very) brief overview of the model. Please check the paper for the details of the model and further analysis on how these components make contributions to the dialog system.
- The incoming user utterance is embedded into a query vector. The model first reads the memory (at top-left) to find relevant history and produce attention weights. Then it generates an output vector by taking the weighted sum followed by a linear transformation. This part is just the original MemN2N.
- Part (1) is Profile Embedding: the profile vector $p$ is added to the query at each iteration, and is also used to revise the candidate responses $r$.
- Part (2) is Global Memory: this component (at bottom-left) has an identical structure as the original MemN2N, but it contains history utterances from other similar users.
- Part (3) is Personalized Preference: the bias term is obtained based on the user preference and added to the prediction logits.
BibTex
@inproceedings{Luo2019Personalized,
author = {Luo, Liangchen and Huang, Wenhao and Zeng, Qi and Nie, Zaiqing and Sun, Xu},
title = {Learning Personalized End-to-End Goal-Oriented Dialog},
booktitle = {Proceedings of the 33rd AAAI Conference on Artificial Intelligence},
month = {January},
year = {2019},
address = {Honolulu, Hawaii}
}