Adaptive Gradient Methods with Dynamic Bound of Learning Rate
Abstract
Adaptive optimization methods such as AdaGrad, RMSProp and Adam have been proposed to achieve a rapid training process with an element-wise scaling term on learning rates. Though prevailing, they are observed to generalize poorly compared with Sgd or even fail to converge due to unstable and extreme learning rates. Recent work has put forward some algorithms such as AMSGrad to tackle this issue but they failed to achieve considerable improvement over existing methods. In our paper, we demonstrate that extreme learning rates can lead to poor performance. We provide new variants of Adam and AMSGrad, called AdaBound and AMSBound respectively, which employ dynamic bounds on learning rates to achieve a gradual and smooth transition from adaptive methods to Sgd and give a theoretical proof of convergence. We further conduct experiments on various popular tasks and models, which is often insufficient in previous work. Experimental results show that new variants can eliminate the generalization gap between adaptive methods and Sgd and maintain higher learning speed early in training at the same time. Moreover, they can bring significant improvement over their prototypes, especially on complex deep networks. The implementation of the algorithm can be found at https://github.com/Luolc/AdaBound.
TL;DR: A Faster And Better Optimizer with Highly Robust Performance
Background
Since proposed in 1950s, Sgd (Robbins & Monro, 1951) has performed well across many deep learning applications in spite of its simplicity. However, there is a disadvantage of Sgd that it scales the gradient uniformly in all directions, which may lead to limited training speed as well as poor performance when the training data are sparse. To address this problem, recent work has proposed a variety of adaptive methods that scale the gradient by square roots of some form of the average of the squared values of past gradients. Examples include Adam (Kingma & Lei Ba, 2015), AdaGrad (Duchi et al., 2011) and RMSprop (Tieleman & Hinton, 2012). Adam in particular has become the default algorithm leveraged across many deep learning frameworks due to its rapid training speed.
Despite their popularity, the generalization ability and out-of-sample behavior of these adaptive methods are likely worse than their non-adaptive counterparts. They often display faster progress in the initial portion of the training, but their performance quickly plateaus on the unseen data (development/test set) (Wilson et al., 2017). Indeed, the optimizer is chosen as Sgd in several recent state-of-the-art works in NLP and CV, wherein these instances Sgd does perform better than adaptive methods. Some researchers devoted to solving this problem in some latest studies. For instance, in the best paper of ICLR 2018 (Reddi et al., 2018), the authors proposed a variant of Adam called AMSGrad, hoping to solve this problem. However, they only provided a theoretical proof of convergence while other researchers found that a considerable performance gap still exists between AMSGrad and Sgd (Keskar & Socher, 2017; Chen et al., 2018).
All of us are hoping to train models faster and better. But it seems that we are not able to achieve this easily by now, or at least we have to fine-tune the hyperparameters of optimizers very carefully. A new optimizer that is as fast as Adam and as good as Sgd is well required by the community.
Extreme Learning Rates Are Evil
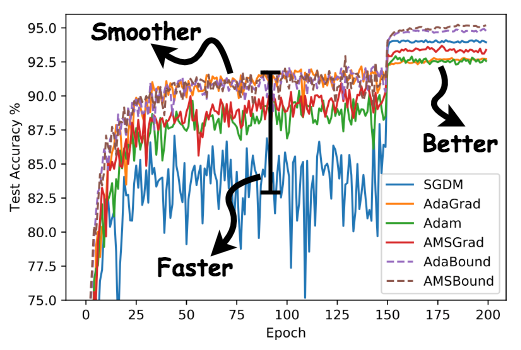
The first attempt to systematically compare the performances of popular adaptive and non-adaptive optimizers is Wilson et al. (2017), which formally pointed out the performance issue of adaptive methods. The authors speculated that the lack of generalization ability of adaptive methods may stem from unstable and extreme learning rates. However, they did not provide further theoretical analysis or empirical study on the hypothesis.
Along this direction, we conduct a preliminary experiment by sampling learning rates of several weights and biases of ResNet-34 on CIFAR-10 using Adam.
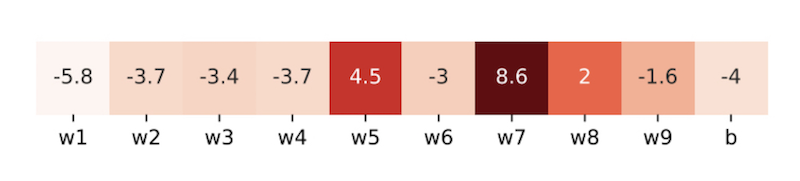
Figure 1: Learning rates of sampled parameters. Each cell contains a value obtained by conducting a logarithmic operation on the learning rate. The lighter cell stands for the smaller learning rate.
We find that when the model is close to convergence, learning rates are composed of tiny ones less than 0.01 as well as huge ones greater than 1000. This observation show that there are indeed learning rates which are too large or too small in the final stage of the training process. But insofar we still have two doubts: (1) does the tiny learning rate really do harm to the convergence of Adam? (2) as the (actual) learning rate highly depends on the initial step size, can we use a relatively larger initial step size to get rid of too small learning rates?
We thereby go further into the theoretical aspect and prove that:
Theorem 3. For any constant $\beta_1, \beta_2 \in [0, 1)$ such that $\beta_1 < \sqrt{\beta_2}$, there is a stochastic convex optimization problem where for any initial step size $\alpha$, Adam does not converge to the optimal solution.
This result illustrates the potential bad impact of extreme learning rates and algorithms are unlikely to achieve good generalization ability without solving this problem. We need to somehow restrict the learning rates of Adam at the final stage of training.
Applying Dynamic Bound on Learning Rates
To address the problem, we need develop a new variant of optimization methods. Our aim is to devise a strategy that combines the benefits of adaptive methods, viz. fast initial progress, and the good final generalization properties of Sgd. Intuitively, we would like to construct an algorithm that behaves like adaptive methods early in training and like Sgd at the end.
We therefore propose the variants of Adam and AMSGrad, called AdaBound and AMSBound by applying dynamic bound on learning rates. Inspired by gradient clipping, a popular technique in practice that clips the gradients larger than a threshold to avoid gradient explosion, we may also employ clipping on learning rates in Adam to propose AdaBound. Consider applying the following operation in Adam $$ \mathrm{Clip}(\alpha / \sqrt{V_t}, \eta_l, \eta_u),$$ which clips the learning rate element-wisely such that the output is constrained to be within the lower bound $\eta_l$ and the upper bound $\eta_u$. It follows that Sgd(M) with the step size $\alpha^*$ can be considered as the case where $\eta_l = \eta_u = \alpha^*$. As for Adam, $\eta_l = 0$ and $\eta_u = \infty$. To achieve a gradual transformation from Adam to Sgd, we can employ $\eta_l$ and $\eta_u$ as functions of $t$ instead of constant values, where $\eta_l(t)$ is a non-decreasing function that starts from $0$ as $t = 0$ and converges to $\alpha^*$ asymptotically; and $\eta_u(t)$ is a non-increasing function that starts from $\infty$ as $t = 0$ and also converges to $\alpha^*$ asymptotically. In this setting, AdaBound behaves just like Adam at the beginning as the bounds have very little impact on learning rates, and it gradually transforms to Sgd(M) as the bounds become more and more restricted. The AMSBound optimizer is obtained by employing similar approach on AMSGrad.
Experiment Results
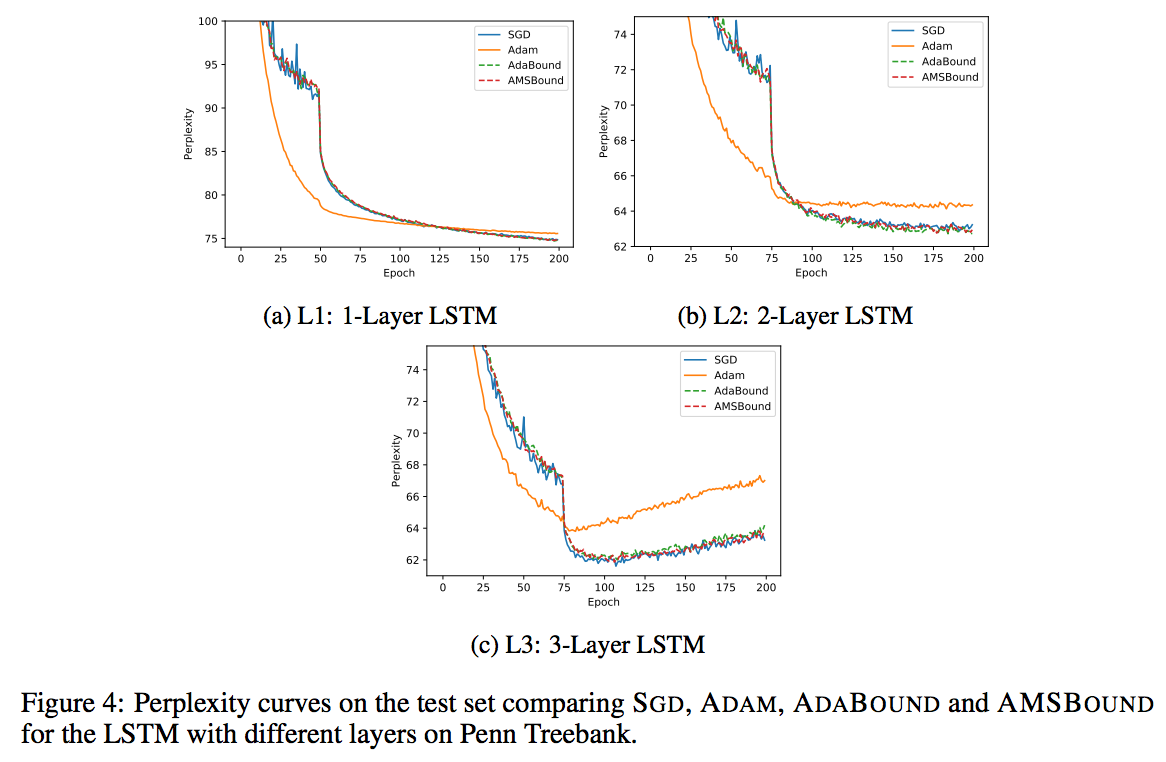
We conduct empirical study of different models to compare new variants with popular methods including: Sgd(M), AdaGrad, Adam and AMSGrad. Here we just provide several learning curve figures for a direct and shallow illustration. Please check the paper for the details of the experiment settings and further analysis.
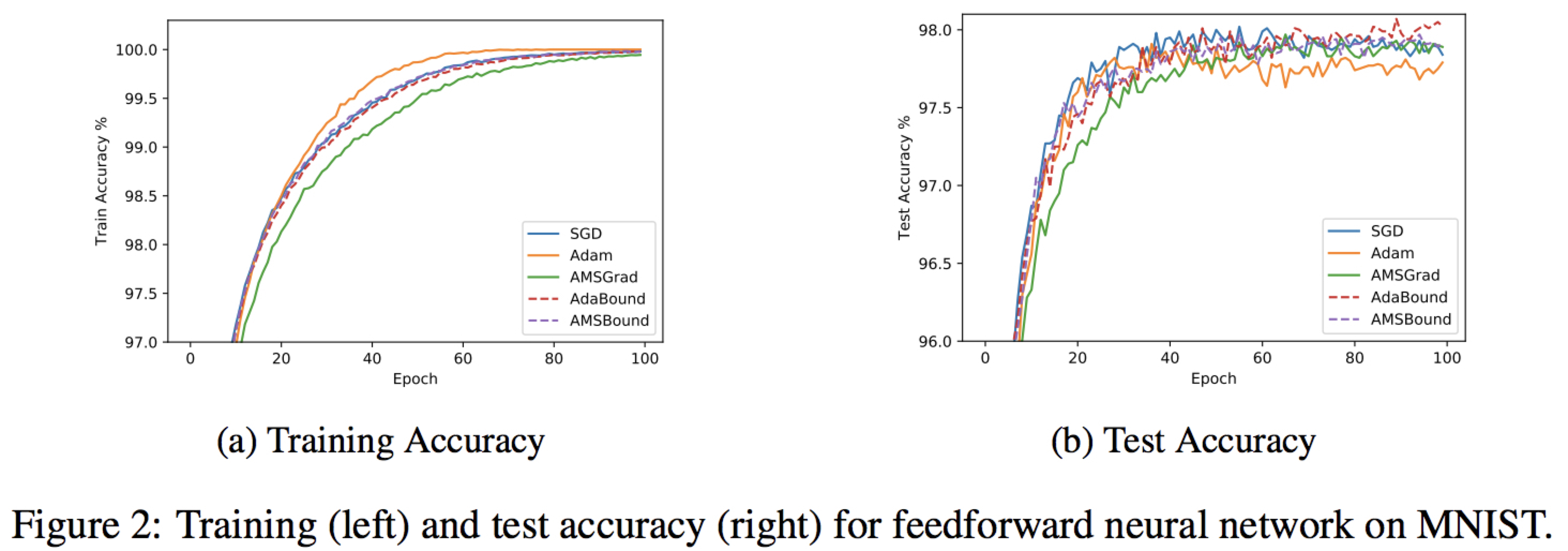
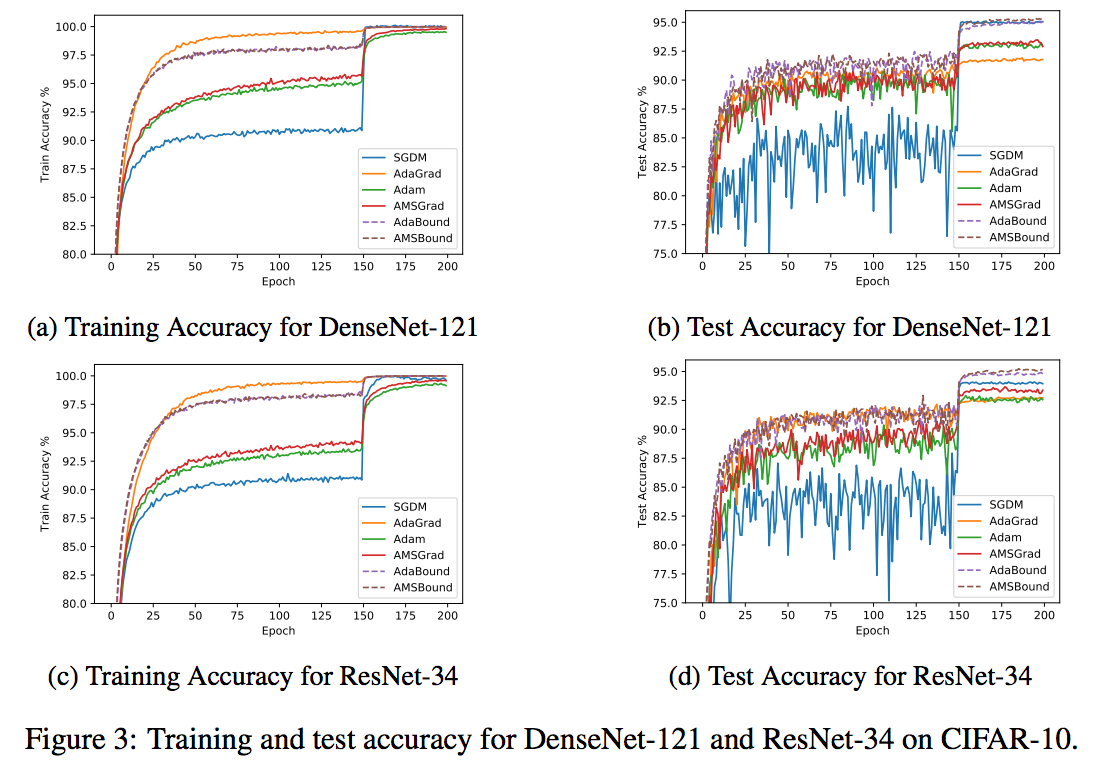
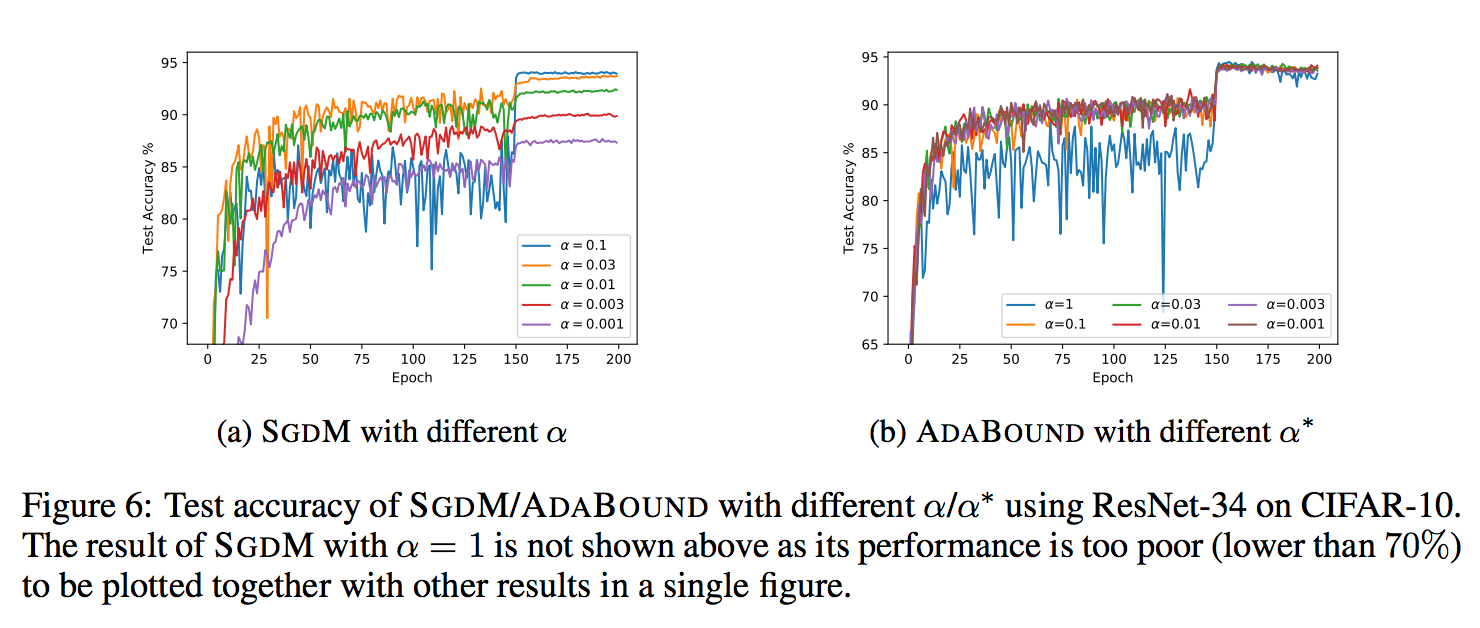
Robust Performance
We also find an interesting property of AdaBound: It is not very sensitive to the hyperparameters,
especially compared with Sgd(M).
This result is very surprising and exciting, for it may translate to a robust performance of AdaBound.
We may spent less time fine-tuning the damned hyperparameters by using this lovely new optimizer!
In common cases, a default final learning rate of 0.1 can achieve relatively good and stable results on unseen data.
Despite of its robust performance, we still have to state that, there is no silver bullet. It does not mean that you will be free from tuning hyperparameters once using AdaBound. The performance of a model depends on so many things including the task, the model structure, the distribution of data, and etc. You still need to decide what hyperparameters to use based on your specific situation, but you may probably use much less time than before!
Code and Demo
We release the code of AdaBound on GitHub, built on PyTorch.
You can install AdaBound easily via pip or directly copying and pasting the source code into your
project.
Besides, thanks to the awesome work by the GitHub team and the Jupyter team, the Jupyter notebook (.ipynb)
files can render directly on GitHub.
We provide several notebooks (like this one)
for better visualization.
We hope to illustrate the robust performance of AdaBound through these examples.
BibTex
@inproceedings{Luo2019AdaBound,
author = {Luo, Liangchen and Xiong, Yuanhao and Liu, Yan and Sun, Xu},
title = {Adaptive Gradient Methods with Dynamic Bound of Learning Rate},
booktitle = {Proceedings of the 7th International Conference on Learning Representations},
month = {May},
year = {2019},
address = {New Orleans, Louisiana}
}